// filenamemacro=chansttu.bas
--- cut here: end ----------------------------------------------------
--- cut here: begin --------------------------------------------------
// DEF PROCStringChangeConvertTranscriptionToUnicode( arrayMinI%, arrayMaxI%, s$, xScreenI%, yScreenI%, xScreenMinI%, xScreenMaxI%, yScreenMinI%, yScreenMaxI%, xScreenStepI%, yScreenStepI% )
--- cut here: end ----------------------------------------------------
--- cut here: begin --------------------------------------------------
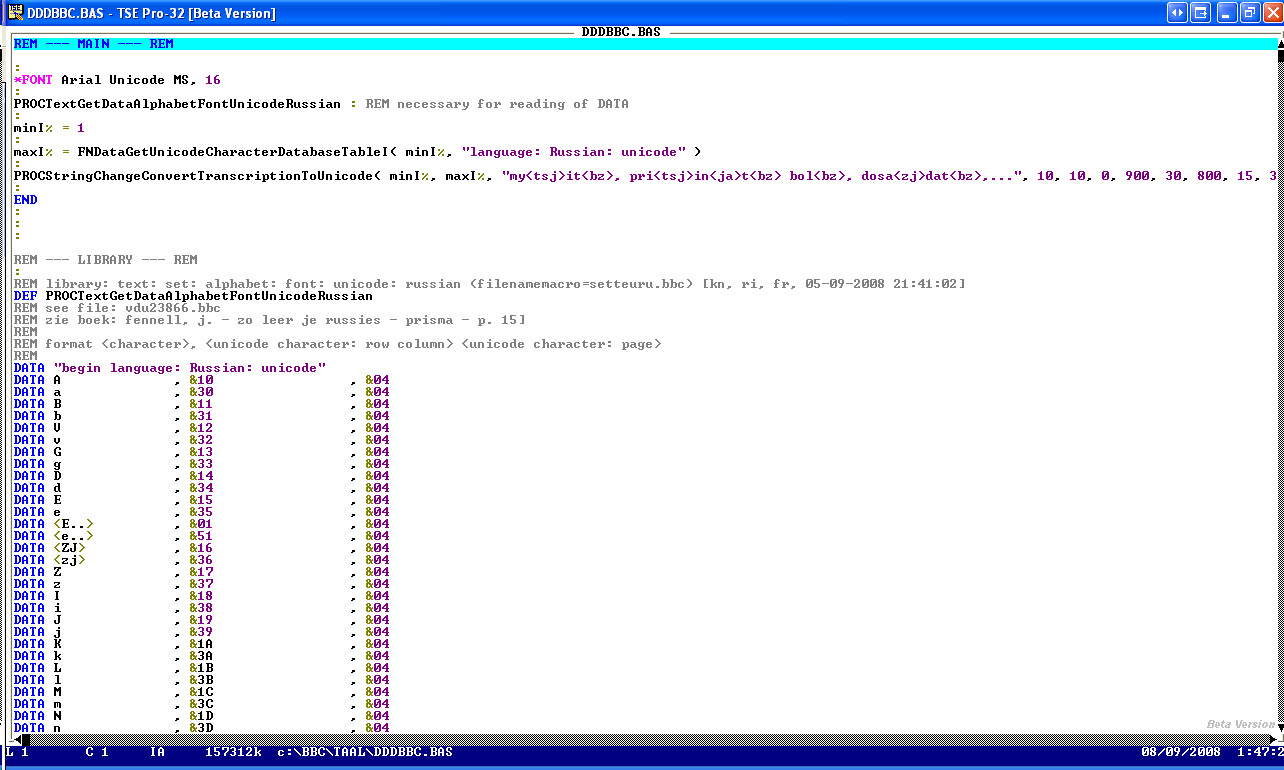
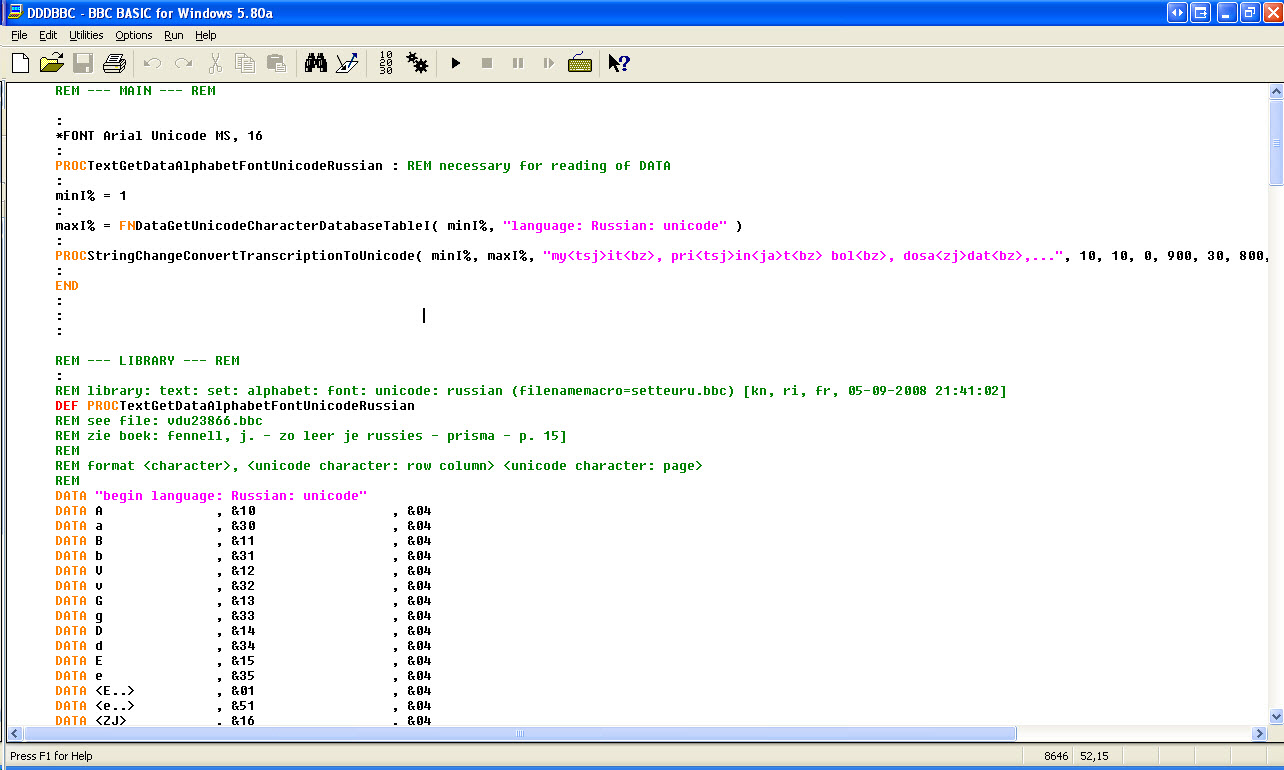
REM --- MAIN --- REM
:
*FONT Arial Unicode MS, 16
:
PROCTextGetDataAlphabetFontUnicodeRussian : REM necessary for reading of DATA
:
minI% = 1
:
maxI% = FNDataGetUnicodeCharacterDatabaseTableI( minI%, "language: Russian: unicode" )
:
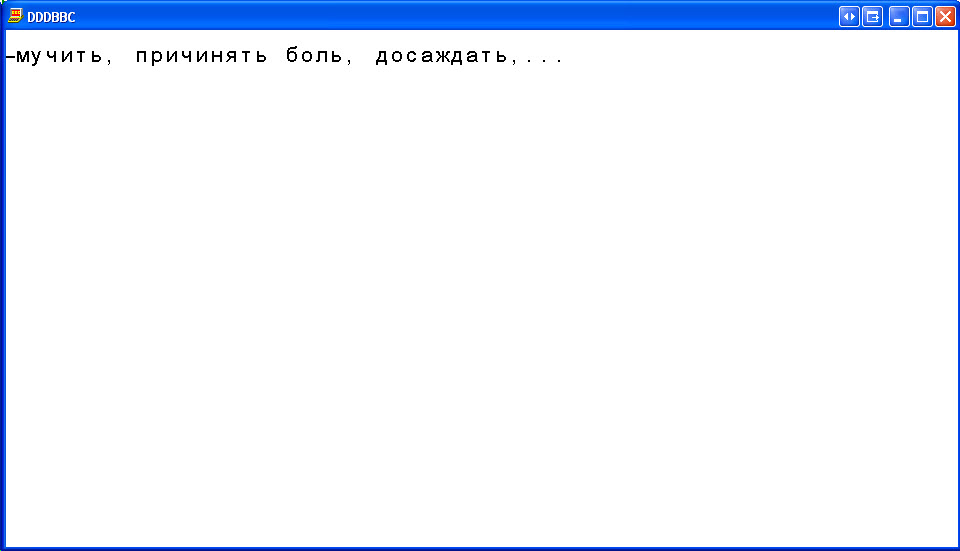
PROCStringChangeConvertTranscriptionToUnicode( minI%, maxI%, "my<tsj>it<bz>, pri<tsj>in<ja>t<bz> bol<bz>, dosa<zj>dat<bz>,...", 10, 10, 0, 900, 30, 800, 15, 30 )
:
END
:
:
:
REM --- LIBRARY --- REM
:
REM library: text: set: alphabet: font: unicode: russian <version>1.0.0.0.0</version> (filenamemacro=setteuru.bbc) [kn, ri, fr, 05-09-2008 21:41:02]
DEF PROCTextGetDataAlphabetFontUnicodeRussian
REM see file: vdu23866.bbc
REM zie boek: fennell, j. - zo leer je russies - prisma - p. 15]
REM
REM format <character>, <unicode character: row column> <unicode character: page>
REM
DATA "begin language: Russian: unicode"
DATA A , &10 , &04
DATA a , &30 , &04
DATA B , &11 , &04
DATA b , &31 , &04
DATA V , &12 , &04
DATA v , &32 , &04
DATA G , &13 , &04
DATA g , &33 , &04
DATA D , &14 , &04
DATA d , &34 , &04
DATA E , &15 , &04
DATA e , &35 , &04
DATA Ë , &01 , &04
DATA ë , &51 , &04
DATA <ZJ> , &16 , &04
DATA <zj> , &36 , &04
DATA Z , &17 , &04
DATA z , &37 , &04
DATA I , &18 , &04
DATA i , &38 , &04
DATA J , &19 , &04
DATA j , &39 , &04
DATA K , &1A , &04
DATA k , &3A , &04
DATA L , &1B , &04
DATA l , &3B , &04
DATA M , &1C , &04
DATA m , &3C , &04
DATA N , &1D , &04
DATA n , &3D , &04
DATA O , &1E , &04
DATA o , &3E , &04
DATA P , &1F , &04
DATA p , &3F , &04
DATA R , &20 , &04
DATA r , &40 , &04
DATA S , &21 , &04
DATA s , &41 , &04
DATA T , &22 , &04
DATA t , &42 , &04
DATA Y , &23 , &04
DATA y , &43 , &04
DATA F , &24 , &04
DATA f , &44 , &04
DATA X , &25 , &04
DATA x , &45 , &04
DATA <TS> , &26 , &04
DATA <ts> , &46 , &04
DATA <TSJ> , &27 , &04
DATA <tsj> , &47 , &04
DATA <SJ> , &28 , &04
DATA <sj> , &48 , &04
DATA <SJE> , &29 , &04
DATA <sje> , &49 , &04
DATA <BH> , &2A , &04
DATA <bh> , &4A , &04
DATA <BI> , &2B , &04
DATA <bi> , &4B , &04
DATA <BZ> , &2C , &04
DATA <bz> , &4C , &04
DATA E , &2D , &04
DATA e , &4D , &04
DATA <JOE> , &2E , &04
DATA <joe> , &4E , &04
DATA <JA> , &2F , &04
DATA <ja> , &4F , &04
DATA "end language: Russian: unicode"
ENDPROC
:
REM library: data: get: unicode: character: database: table <version>1.0.0.0.0</version> (filenamemacro=getdadta.bbc) [kn, ri, fr, 05-09-2008 18:00:27]
DEF FNDataGetUnicodeCharacterDatabaseTableI( minI%, dataName$ )
REM e.g. :
REM e.g. PROCTextGetDataAlphabetFontUnicodeRussian : REM necessary for reading of DATA
REM e.g. :
REM e.g. PRINT; FNDataGetUnicodeCharacterDatabaseTableI( 1, "language: Russian: unicode" )
REM e.g. :
REM e.g. END
REM e.g. :
REM e.g. :
REM e.g. :
LOCAL s$
LOCAL byte1I%
LOCAL byte2I%
LOCAL stopB%
LOCAL I%
LOCAL maxI%
:
DIM s$( 100, 3 )
:
RESTORE
:
REPEAT
READ s$
stopB% = ( s$ = "begin" + " " + dataName$ )
UNTIL ( stopB% )
:
I% = minI% - 1
:
REPEAT
:
READ s$
:
s$ = FNStringGetSpaceTrimS( s$ )
:
REM PRINT s$
:
stopB% = ( s$ = "end" + " " + dataName$ )
:
IF ( NOT ( stopB% ) ) THEN
:
READ byte1I%
READ byte2I%
:
I% = I% + 1
:
s$( I%, 1 ) = s$
s$( I%, 2 ) = STR$( byte1I% )
s$( I%, 3 ) = STR$( byte2I% )
:
ENDIF
:
ENDIF
:
UNTIL ( stopB% )
:
maxI% = I%
:
= maxI%
:
REM library: string: change: convert: transcription: to: unicode <version>1.0.0.0.4</version> (filenamemacro=chansttu.bas) [kn, ri, sa, 06-09-2008 01:55:20]
DEF PROCStringChangeConvertTranscriptionToUnicode( arrayMinI%, arrayMaxI%, s$, xScreenI%, yScreenI%, xScreenMinI%, xScreenMaxI%, yScreenMinI%, yScreenMaxI%, xScreenStepI%, yScreenStepI% )
REM e.g. :
REM e.g. *FONT Arial Unicode MS, 16
REM e.g. :
REM e.g. PROCTextGetDataAlphabetFontUnicodeRussian : REM necessary for reading of DATA
REM e.g. :
REM e.g. minI% = 1
REM e.g. :
REM e.g. maxI% = FNDataGetUnicodeCharacterDatabaseTableI( minI%, "language: Russian: unicode" )
REM e.g. :
REM e.g. PROCStringChangeConvertTranscriptionToUnicode( minI%, maxI%, "my<tsj>it<bz>, pri<tsj>in<ja>t<bz> bol<bz>, dosa<zj>dat<bz>,...", 10, 10, 0, 900, 30, 800, 15, 30 )
REM e.g. :
REM e.g. END
REM e.g. :
REM e.g. :
REM e.g. :
:
REM +--------------<---------------+
REM | |
REM ->-+->-[a-zA-Z]->-----------------+->-
REM | |
REM +->-(<)-+->-[a-zA-Z]->-+-(>)->-+
REM | |
REM +-------<------+
:
LOCAL I%
LOCAL c$
LOCAL w$
LOCAL minI%
LOCAL lengthI%
LOCAL stopB%
LOCAL byte1I%
LOCAL byte2I%
LOCAL arrayI%
:
lengthI% = LEN( s$ )
:
w$ = ""
:
minI% = 1
:
I = minI% - 1
:
WHILE ( NOT ( stopB% ) )
:
I% = I% + 1
:
c$ = MID$( s$, I%, 1 )
:
IF ( c$ = "<" ) THEN
REPEAT
w$ = w$ + c$
I% = I% + 1
c$ = MID$( s$, I%, 1 )
UNTIL ( ( c$ = ">" ) OR ( I% >= lengthI% ) )
w$ = w$ + c$
ELSE
w$ = w$ + c$
ENDIF
:
arrayI% = FNStringGetUnicodeCharacterSearchRowI( w$, arrayMinI%, arrayMaxI% )
:
IF ( arrayI% >= arrayMinI% ) THEN
byte1I% = EVAL( s$( arrayI%, 2 ) )
byte2I% = EVAL( s$( arrayI%, 3 ) )
ELSE
byte1I% = ASC( c$ )
byte2I% = 0
ENDIF
:
PROCTextViewUnicodeByteTwo( byte1I%, byte2I%, xScreenI%, yScreenI% )
REPEAT UNTIL GET
:
xScreenI% = xScreenI% + xScreenStepI%
:
IF xScreenI% > xScreenMaxI% THEN
xScreenI% = xScreenMinI%
yScreenI% = yScreenI% + yScreenStepI%
ENDIF
:
w$ = ""
:
stopB% = ( I% >= lengthI% )
:
ENDWHILE
:
ENDPROC
:
REM library: string: get: space: trim <version>1.0.0.0.0</version> (filenamemacro=getststr.bbc) [kn, ri, fr, 05-09-2008 21:34:05]
DEF FNStringGetSpaceTrimS( s$ )
REM e.g. PROCMessage( FNStringGetSpaceTrimS( " abc " ) ) : REM e.g. gives "abc"
REM e.g. END
REM e.g. :
REM e.g. :
REM e.g. :
IF RIGHT$( s$, 1 ) <> " " THEN = s$ ELSE = FNStringGetSpaceTrimS( LEFT$( s$, LEN s$ - 1 ) )
:
REM library: string: get: unicode: character: representation <version>1.0.0.0.0</version> (filenamemacro=getstcre.bbc) [kn, ri, fr, 05-09-2008 22:44:23]
DEF FNStringGetUnicodeCharacterSearchRowI( s$, minI%, maxI% )
LOCAL I%
LOCAL foundB%
:
foundB% = FALSE
:
I% = minI% - 1
:
REPEAT
:
I% = I% + 1
:
foundB% = ( s$ = s$( I%, 1 ) )
:
UNTIL foundB% OR ( I% >= maxI% )
:
IF ( NOT ( foundB% ) ) THEN
REM PRINT "string not found"
REM REPEAT UNTIL GET
I% = -1000
ENDIF
:
= I%
:
REM library: text: view: unicode: byte: two <version>1.0.0.0.0</version> (filenamemacro=viewtebt.bbc) [kn, ri, fr, 05-09-2008 17:56:31]
DEF PROCTextViewUnicodeByteTwo( byte1I%, byte2I%, xScreenI%, yScreenI% )
LOCAL uniCode$
uniCode$ = CHR$( byte1I% ) + CHR$( byte2I% )
SYS "TextOutW", @memhdc%, xScreenI%, yScreenI%, uniCode$, LEN( uniCode$ ) / 2
SYS "InvalidateRect", @hwnd%, 0, 0
ENDPROC
:
REM library: message <version>1.0.0.0.0</version> (filenamemacro=memessag.bbc) [kn, ri, fr, 05-05-2006 18:38:23]
DEF PROCMessage( s$ )
REM e.g. PROCMessage( "test" ) : REM gives 'test'
REM e.g. END
REM e.g. :
REM e.g. :
REM e.g. :
PRINT s$
ENDPROC
--- cut here: end ----------------------------------------------------
7. -Run the program
8. -Tested successfully on
Microsoft Windows XP Professional (service pack 3),
running
BBCBASIC for Windows
===
Book: see also:
===
Diagram: see also:
===
File: see also:
===
File: version: control: see also:
===
Help: see also:
===
Image: see also:
 ===
Internet: see also:
---
BBCBASIC for Windows: Unicode: Link: Can you give an overview of links?
http://goo.gl/JcUGx
===
Podcast: see also:
===
Record: see also:
===
Screencast: see also:
===
Table: see also:
===
Video: see also:
===
<version>1.0.0.0.3</version>
----------------------------------------------------------------------
===
Internet: see also:
---
BBCBASIC for Windows: Unicode: Link: Can you give an overview of links?
http://goo.gl/JcUGx
===
Podcast: see also:
===
Record: see also:
===
Screencast: see also:
===
Table: see also:
===
Video: see also:
===
<version>1.0.0.0.3</version>
----------------------------------------------------------------------
