----------------------------------------------------------------------
--- Knud van Eeden --- 15 Juny 2008 - 02:20 pm -----------------------
Language: Computer: BASIC: BBCBASIC: Windows: Font: Unicode: Character: World
---
There are 256 times 256, or thus 65536 characters possible in UniCode.
In this range most values are used to represent a character, others not
(these show e.g. an empty square).
---
You will need to use a Unicode font to show the characters (otherwise
you will see e.g. only empty squares).
Typical fonts are
Arial Unicode MS
(which you might have to install from the Microsoft Windows (XP) installation CD, if not present on your system).
This font contains the most Unicode characters.
Another possible Unicode font is
Tahoma
---
To draw a character, you will need to choose the first byte and the
second byte, and its xy position on the screen.
---
The languages are mostly bundled in groups of 256 characters.
E.g. Greek is in group 3, Russian is in group 4 of the totally 256 groups.
---
Usually the value is given in hexadecimal, because you can split that
number in 2 independent parts, which simplifies your calculations (e.g.
in your head).
---
E.g. character &0628 you split in &06 and &28 hexadecimal.
The first number gives the page (e.g. page 6).
The second number gives the position on that page (e.g. &28 is thus 40
decimal), between 0 and 255.
---
Here a few example programs, starting with the simplest possibility,
that is 1 character.
---
The random example varies randomly the xy position of that 1 character
on the screen, and also the value of that character (between 0 and 255
for the first byte, and 0 and 255 for the second byte, thus totally
between 0 and 65535).
---
The last example gives you an overview of all the possible Unicode
characters (that is 256 pages of 256 characters, or thus 65536
characters).
---
Note that you clearly see that the writings of some seemingly difficult
looking languages like Arabic, Hindi, ... clearly are built up of the
much simpler single characters, similar to the way we build sentences
in the Latin alphabet, by concatenating single alphabet characters to
strings. This insight could possibly boost your comprehension and speed
up your learning of that language.
===
Program: Simplest <author> Richard T. Russell </author> [kn, ri, su, 15-06-2008 16:50:38]
--- cut here: begin --------------------------------------------------
*FONT Tahoma, 16
xScreenI% = 50
yScreenI% = 50
REM shows Farsi character &0628 using Unicode font
Unicode$ = CHR$&28 + CHR$ &06
SYS "TextOutW", @memhdc%, xScreenI%, yScreenI%, Unicode$, LEN( Unicode$ ) / 2
SYS "InvalidateRect", @hwnd%, 0, 0
--- cut here: begin --------------------------------------------------
===
Program: Simple, using procedure instead
--- cut here: begin --------------------------------------------------
*FONT Tahoma, 16
:
REM shows Farsi character &0628 using Unicode font
PROCUnicodeCharacter( &06, &28, 50, 50 )
:
END
:
:
:
DEF PROCUnicodeCharacter( byte1I%, byte2I%, xScreenI%, yScreenI% )
LOCAL uniCode$
uniCode$ = CHR$( byte2I% ) + CHR$( byte1I% )
SYS "TextOutW", @memhdc%, xScreenI%, yScreenI%, uniCode$, LEN( uniCode$ ) / 2
SYS "InvalidateRect", @hwnd%, 0, 0
ENDPROC
--- cut here: end ----------------------------------------------------
===
Program: Drawing random Unicode characters on random position on the screen
--- cut here: begin --------------------------------------------------
*FONT Tahoma, 16
REM *FONT Arial Unicode MS, 16
REPEAT
xScreenI% = RND( 1000 )
yScreenI% = RND( 500 )
byte1I% = RND( 256 ) - 1
byte2I% = RND( 256 ) - 1
Unicode$ = CHR$( byte1I% ) + CHR$( byte2I% )
SYS "TextOutW", @memhdc%, xScreenI%, yScreenI%, Unicode$, LEN( Unicode$ ) / 2
SYS "InvalidateRect", @hwnd%, 0, 0
UNTIL FALSE
--- cut here: end ----------------------------------------------------
===
Program: Showing the 256 Unicode pages of totally 256 characters each
(totalling 256 x 256 = 65536 possibilities)
--- cut here: begin --------------------------------------------------
REM you must have a UniCode font installed
REM Check this e.g. in 'Control panel'->'Fonts'
REM (if not, install e.g. from the Microsoft (XP) CD)
REM (choose 'Install new font' in the 'File' menu
REM in the 'control panel' 'fonts' screen))
:
REM *FONT Tahoma, 16
:
*FONT Arial Unicode MS, 16
:
PROCUnicodePageAll( 0, 470, 30, 500, 30, 30 )
END
:
:
:
DEF PROCUnicodePageAll( xScreenMinI%, xScreenMaxI%, yScreenMinI%, yScreenMaxI%, xScreenStepI%, yScreenStepI% )
LOCAL byte1I%
LOCAL byte2I%
LOCAL xScreenI%
LOCAL yScreenI%
:
FOR byte2I% = 0 TO 255
:
xScreenI% = xScreenMinI%
yScreenI% = yScreenMinI%
:
CLG
:
PRINT TAB( 0, 0 );
PRINT; "language font unicode block (0-255) = "; byte2I%;
PRINT; " : <press any key>"
:
FOR byte1I% = 0 TO 255
:
PROCUnicode( byte1I%, byte2I%, xScreenI%, yScreenI% )
:
xScreenI% += xScreenStepI%
:
IF xScreenI% > xScreenMaxI% THEN
xScreenI% = xScreenMinI%
yScreenI% = yScreenI% + yScreenStepI%
ENDIF
:
NEXT byte1I%
:
REPEAT UNTIL GET
:
NEXT byte2I%
:
ENDPROC
:
DEF PROCUnicode( byte1I%, byte2I%, xScreenI%, yScreenI% )
LOCAL uniCode$
uniCode$ = CHR$( byte1I% ) + CHR$( byte2I% )
SYS "TextOutW", @memhdc%, xScreenI%, yScreenI%, uniCode$, LEN( uniCode$ ) / 2
SYS "InvalidateRect", @hwnd%, 0, 0
ENDPROC
:
--- cut here: end ----------------------------------------------------
===
Program: Showing the 256 Unicode pages of totally 256 characters each
(totalling 256 x 256 = 65536 possibilities)
with a description of the languages used on this page
and the hexadecimal position of each character on each page.
--- cut here: begin --------------------------------------------------
REM --- MAIN --- REM
REM you must have a UniCode font installed
REM Check this e.g. in 'Control panel'->'Fonts'
REM (if not, install e.g. from the Microsoft (XP) CD)
REM (choose 'Install new font' in the 'File' menu
REM in the 'control panel' 'fonts' screen))
:
REM *FONT Tahoma, 16
:
*FONT Arial Unicode MS, 11, B
:
PROCDataGetUnicodeLanguagePage
:
PROCTextViewUnicodePageAllCode( 0, 470, 30, 500, 30, 30 )
END
:
:
:
REM --- LIBRARY --- REM
:
REM library: text: view: unicode: page: all: code <description>View all Unicode pages (including hexadecimal position code)</description> (filenamemacro=viewteac.bbc) [kn, ri, su, 04-01-2009 22:00:33]
DEF PROCTextViewUnicodePageAllCode( xScreenMinI%, xScreenMaxI%, yScreenMinI%, yScreenMaxI%, xScreenStepI%, yScreenStepI% )
REM e.g. REM you must have a UniCode font installed
REM e.g. REM Check this e.g. in 'Control panel'->'Fonts'
REM e.g. REM (if not, install e.g. from the Microsoft (XP) CD)
REM e.g. REM (choose 'Install new font' in the 'File' menu
REM e.g. REM in the 'control panel' 'fonts' screen))
REM e.g. :
REM e.g. REM *FONT Tahoma, 16
REM e.g. :
REM e.g. *FONT Arial Unicode MS, 11, B
REM e.g. :
REM e.g. PROCDataGetUnicodeLanguagePage
REM e.g. :
REM e.g. PROCTextViewUnicodePageAllCode( 0, 470, 30, 500, 30, 30 )
REM e.g. END
REM e.g. :
REM e.g. :
REM e.g. :
LOCAL byte1I%
LOCAL byte2I%
LOCAL xScreenI%
LOCAL yScreenI%
LOCAL s$
:
FOR byte2I% = 0 TO 255
:
xScreenI% = xScreenMinI%
yScreenI% = yScreenMinI%
:
CLG
:
READ s$
*FONT Arial Unicode MS, 8
PRINT TAB( 0, 0 ); "content of this code page = "; s$
PRINT TAB( 0, 1 );
PRINT; "language font unicode block (0-255) = "; byte2I%;
COLOUR 1
PRINT; " (=page &"; STR$ ~byte2I%; ")";
COLOUR 0
PRINT; " : <press any key>"
*FONT Arial Unicode MS, 11, B
:
FOR byte1I% = 0 TO 255
:
PROCUnicode( byte1I%, byte2I%, xScreenI%, yScreenI% )
:
VDU 5
GCOL 0,1
MOVE xScreenI% * 2, 1000 - yScreenI% * 2
*FONT Arial Unicode MS, 8
PRINT; "&"; STR$ ~byte1I%
*FONT Arial Unicode MS, 11, B
VDU 4
:
xScreenI% += xScreenStepI%
:
IF xScreenI% > xScreenMaxI% THEN
xScreenI% = xScreenMinI%
yScreenI% = yScreenI% + yScreenStepI%
ENDIF
:
NEXT byte1I%
:
REPEAT UNTIL GET
:
NEXT byte2I%
:
ENDPROC
:
DEF PROCUnicode( byte1I%, byte2I%, xScreenI%, yScreenI% )
LOCAL uniCode$
uniCode$ = CHR$( byte1I% ) + CHR$( byte2I% )
SYS "TextOutW", @memhdc%, xScreenI%, yScreenI%, uniCode$, LEN( uniCode$ ) / 2
SYS "InvalidateRect", @hwnd%, 0, 0
ENDPROC
:
REM library: data: get: unicode: language: page <description></description> (filenamemacro=getdalpa.bbc) [kn, ri, su, 04-01-2009 23:06:02]
DEF PROCDataGetUnicodeLanguagePage
DATA Basic Latin; Latin-1 supplement
DATA Latin Extended-A; Latin Extended-B
DATA Latin Extended-B; IPA Extensions; Spacing Modifier Letters
DATA Combining Diacritical Marks; Greek and Coptic
DATA Cyrillic
DATA Cyrillic Supplement; Armenian; Hebrew
DATA Arabic
DATA Syriac; Arabic Supplement; Thaana; N'Ko (Mandenkan)
DATA Unused page
DATA Devanagari; Bengali
DATA Gurmukhi; Gujarati
DATA Oriya; Tamil
DATA Telugu; Kannada
DATA Malayalam; Sinhala
DATA Thai; Lao
DATA Tibetan
DATA Burmese (Myanmar); Georgian
DATA Hangul Jamo
DATA Ethiopic
DATA Ethiopic; Ethiopic Supplement; Cherokee
DATA Unified Canadian Aboriginal Syllabics
DATA Unified Canadian Aboriginal Syllabics
DATA Unified Canadian Aboriginal Syllabics; Ogham; Runic
DATA Tagalog; Hanunóo; Buhid; Tagbanwa; Khmer
DATA Mongolian
DATA Limbu; Tai Le; New Tai Lue; Khmer Symbols
DATA Buginese
DATA Balinese; Sundanese
DATA Lepcha (Rong); Ol Chiki (Santali / Ol Cemet')
DATA Phonetic Extensions; Diacrital marks
DATA Latin Extended Additional
DATA Greek Extended
DATA Punctuation; Superscripts; Subscripts; Currency; Diacritics
DATA Letterlike Symbols; Number Forms; Arrows
DATA Mathematical Operators
DATA Miscellaneous Technical
DATA Control Pictures; Optical Character Recognition; Enclosed Alphanumerics
DATA Box Drawing; Block Elements; Geometric Shapes
DATA Miscellaneous Symbols
DATA Dingbats; Mathematical Symbols-A; Supplemental Arrows-A
DATA Braille Patterns
DATA Supplemental Arrows-B; Mathematical Symbols-B
DATA Supplemental Mathematical Operators
DATA Miscellaneous Symbols and Arrows
DATA Glagolitic; Latin Extended-C; Coptic
DATA Georgian Supplement; Tifinagh; Ethiopic Extended; Cyrillic Extended-A
DATA Supplemental Punctuation; CJK Radicals Supplement
DATA Kangxi Radicals; Ideographic Description Characters
DATA CJK Symbols and Punctuation; Hiragana; Katakana
DATA Bopomofo; Hangul Compatibility Jamo; Kanbun; Bopomofo Extended; CJK Strokes; Katakana Phonetic Extensions
DATA Enclosed CJK Letters and Months
DATA CJK Compatibility
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A
DATA CJK Unified Ideographs Extension A; Yijing Hexagram Symbols
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA CJK Unified Ideographs
DATA Yi Syllables
DATA Yi Syllables
DATA Yi Syllables
DATA Yi Syllables
DATA Yi Syllables; Yi Radicals
DATA Vai
DATA Vai; Cyrillic Extended-B
DATA Modifier Tone Letters; Latin Extended-D
DATA Syloti Nagri; Phags-pa; Saurashtra
DATA Kayah Li; Rejang
DATA Cham
DATA Unused page
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA Hangul Syllables
DATA High Surrogates
DATA High Surrogates
DATA High Surrogates
DATA High Surrogates; High Private Use Surrogates
DATA Low Surrogates
DATA Low Surrogates
DATA Low Surrogates
DATA Low Surrogates
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA Private Use Area
DATA CJK Compatibility Ideographs
DATA CJK Compatibility Ideographs
DATA Alphabetic Presentation Forms; Arabic Presentation Forms-A
DATA Alphabetic Presentation Forms; Arabic Presentation Forms-A
DATA Alphabetic Presentation Forms; Arabic Presentation Forms-A
DATA Variation Selectors; Vertical Forms; Half Marks; CJK Compatibility Forms; Small Form Variants; Arabic Presentation Forms-B
DATA Halfwidth and Fullwidth Forms; Specials
ENDPROC
:
--- cut here: end ----------------------------------------------------
===
Book: see also:
===
Diagram: see also:
===
Help: see also:
===
Image: see also:
Single UniCode character
 Single UniCode character with supplemental information
Single UniCode character with supplemental information
 Random unicode characters
Random unicode characters
 Ascii
Ascii
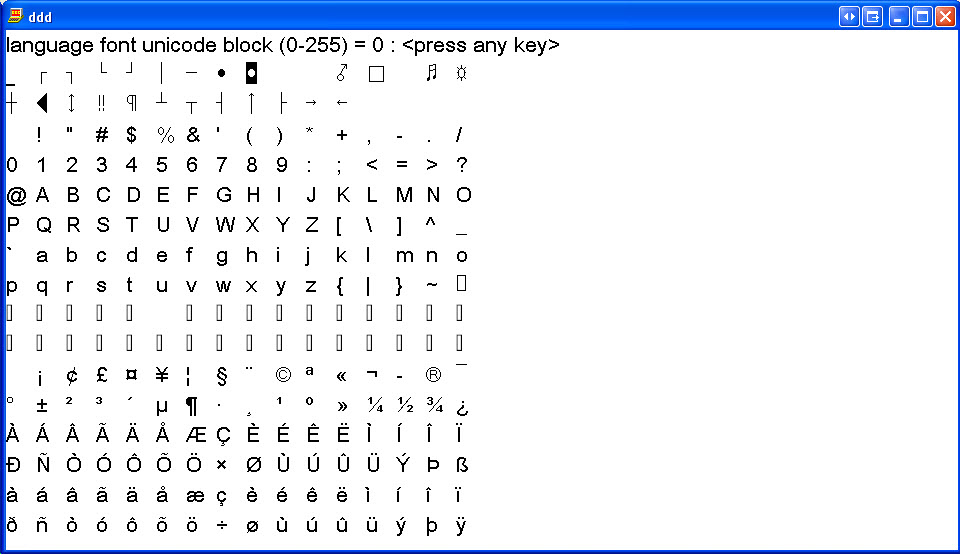 East European, Welsh, ...
East European, Welsh, ...
 Greek
Greek
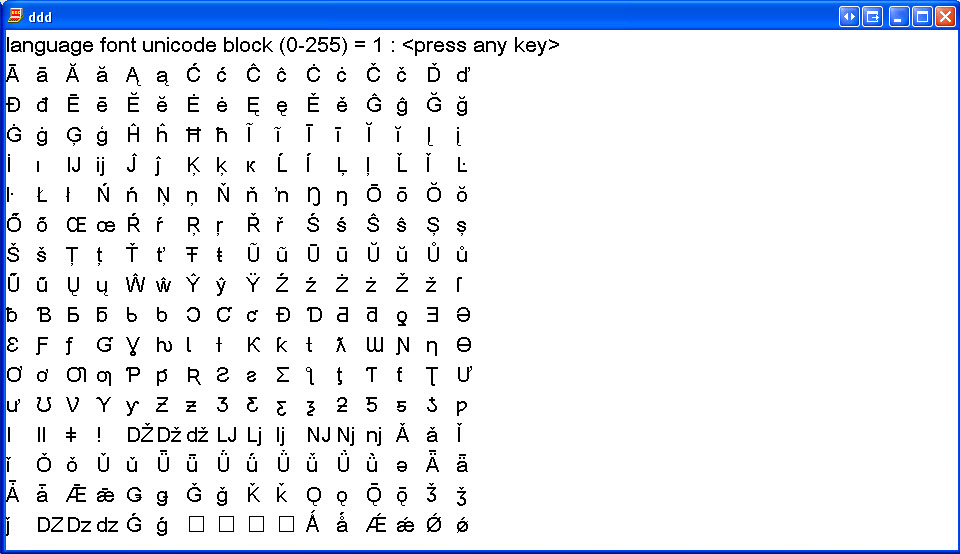
 Russian (Cyrillic)
Russian (Cyrillic)
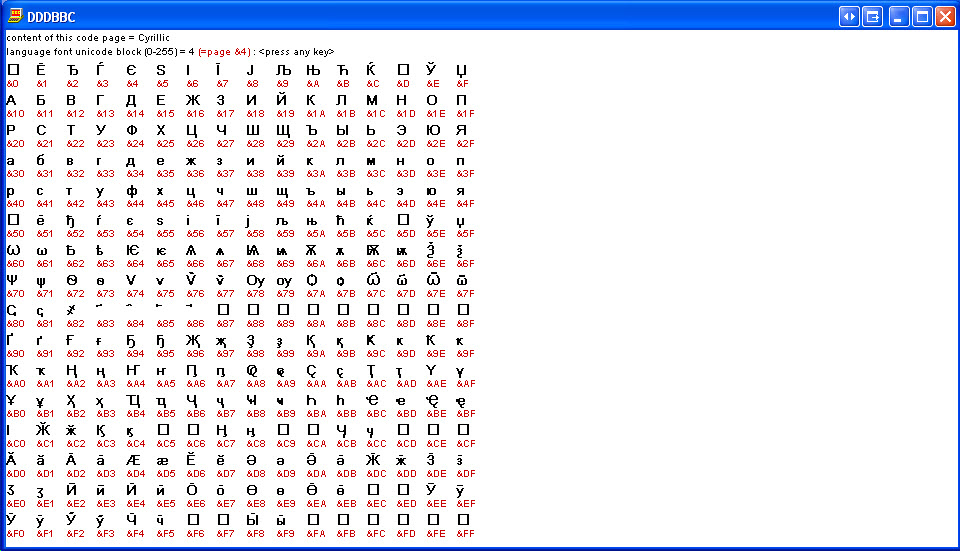
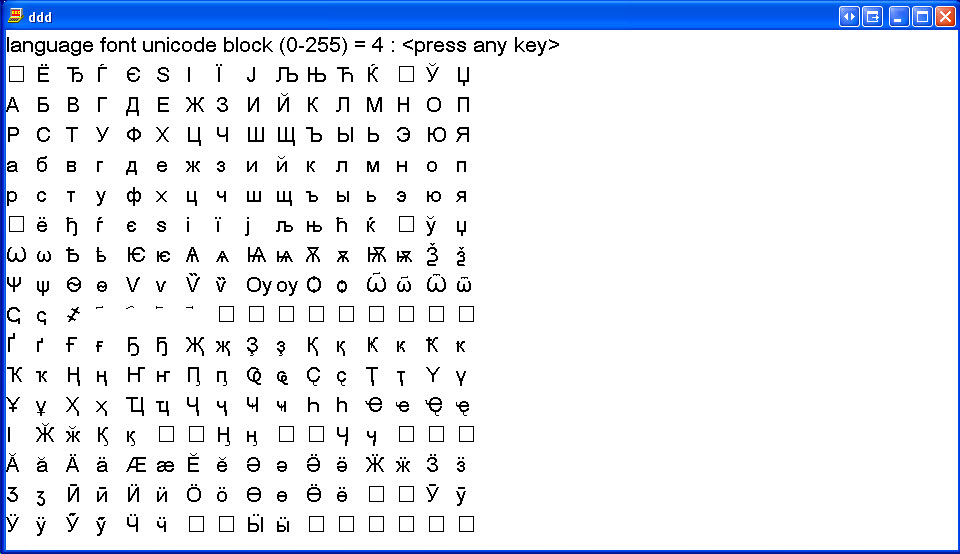 Russian (Cyrillic) with supplemental information
Russian (Cyrillic) with supplemental information
 Hebrew
Hebrew
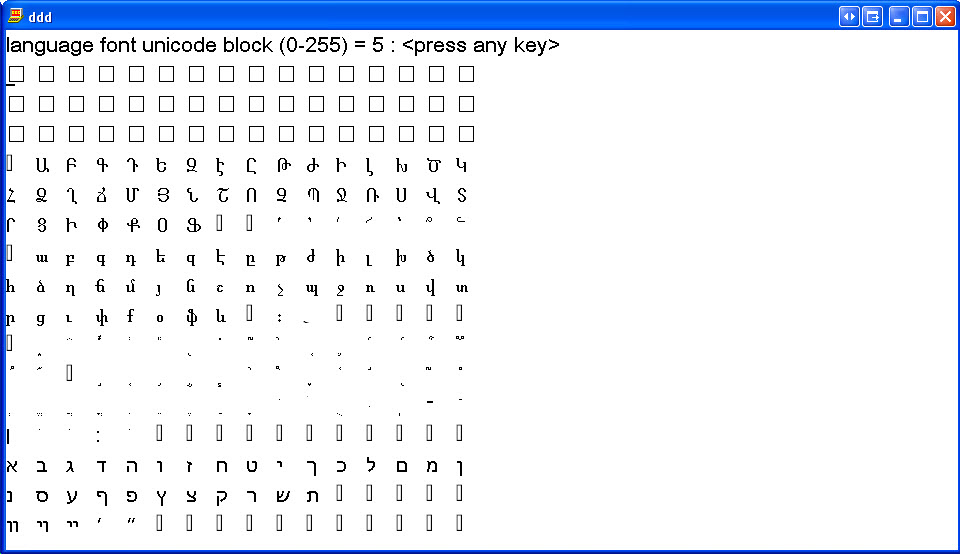 Arabic
Arabic
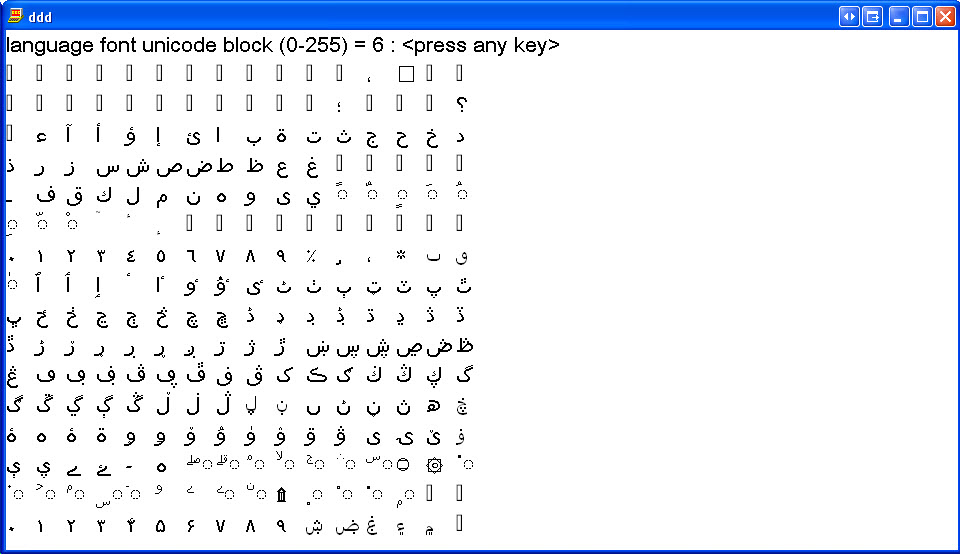 Hindi (India)
Hindi (India)
 Japanese
Japanese
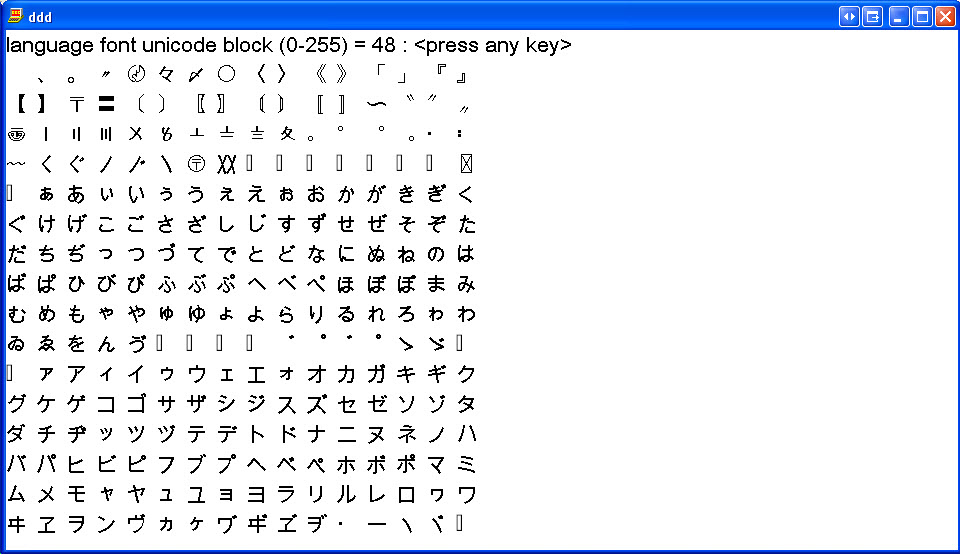 Chinese
Chinese
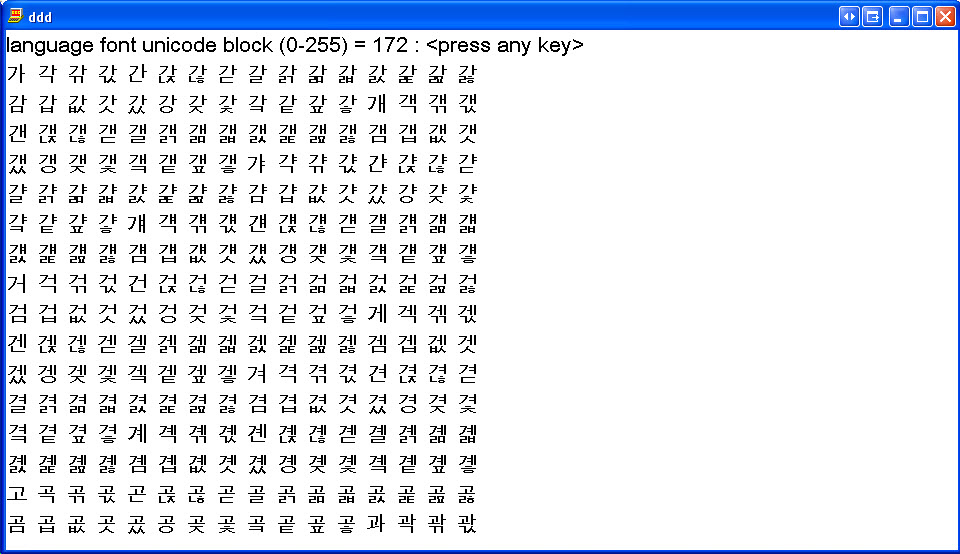
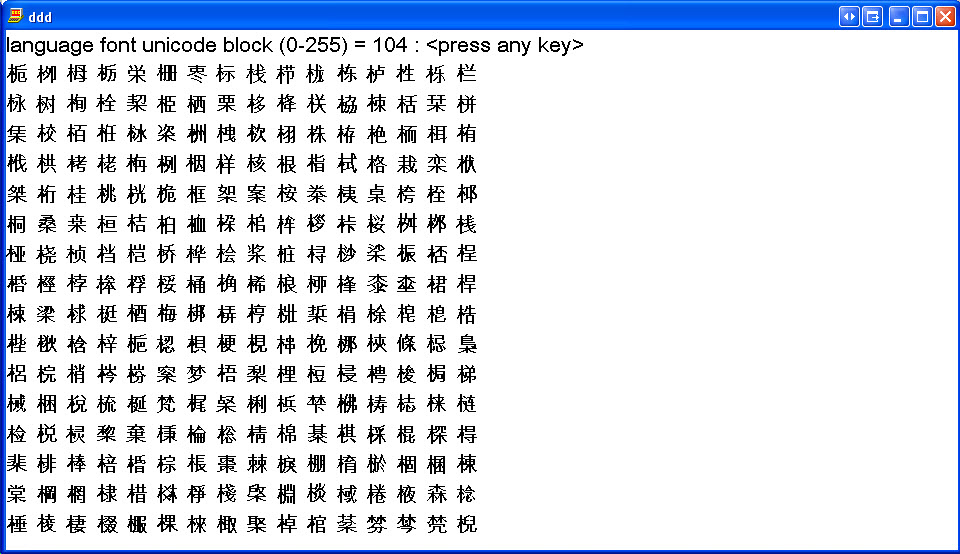 Korean
Korean
 ===
Internet: see also:
Find your Unicode character for your given language: Overview
http://unicode.org/charts/">http://unicode.org/charts/">http://unicode.org/charts/
---
Find your Unicode character for your given language (Latin, Greek, Cyrillic, Armenian, Hebrew, Arabic, Devanagari (India, Nepal), Bengali (India), Gurmukhi (India), Oriya (India), Tamil (Sri Lanka), Telugu (India), Kannada (India), Malayalam, Sinhala (Sri Lanka), Thai, Lao, Tibetan, Myanmar, Georgian, Hangul (Korea), Hiragana (Japan), Katakana (Japan), Han (simplified Chinese - China), Tifinagh (Berber), Balinese (Bali), ...)
http://www.unicode.org/charts/normalization/
---
Download: Unicode in BBCBASIC (executable)
---
efg's Unicode Lab Report
http://www.efg2.com/Lab/OtherProjects/Unicode.htm
---
Where can I get the Unicode fonts?
http://tlt.its.psu.edu/suggestions/international/web/unicode.html
---
Microsoft Windows: API: TextOutW
http://64.233.183.104/search?q=cache:-hfl5kT4RJ8J:msdn.microsoft.com/en-us/library/ms534019(VS.8
---
Unicode: Delphi
http://www.experts-exchange.com/Programming/Languages/Pascal/Delphi/Q_23279239.html
---
Unicode: Can you give an overview of links?
http://www.faqts.com/knowledge_base/view.phtml/aid/38864/fid/1852
===
Screencast: see also:
===
Table: see also:
===
Video: see also:
---
----------------------------------------------------------------------
===
Internet: see also:
Find your Unicode character for your given language: Overview
http://unicode.org/charts/">http://unicode.org/charts/">http://unicode.org/charts/
---
Find your Unicode character for your given language (Latin, Greek, Cyrillic, Armenian, Hebrew, Arabic, Devanagari (India, Nepal), Bengali (India), Gurmukhi (India), Oriya (India), Tamil (Sri Lanka), Telugu (India), Kannada (India), Malayalam, Sinhala (Sri Lanka), Thai, Lao, Tibetan, Myanmar, Georgian, Hangul (Korea), Hiragana (Japan), Katakana (Japan), Han (simplified Chinese - China), Tifinagh (Berber), Balinese (Bali), ...)
http://www.unicode.org/charts/normalization/
---
Download: Unicode in BBCBASIC (executable)
---
efg's Unicode Lab Report
http://www.efg2.com/Lab/OtherProjects/Unicode.htm
---
Where can I get the Unicode fonts?
http://tlt.its.psu.edu/suggestions/international/web/unicode.html
---
Microsoft Windows: API: TextOutW
http://64.233.183.104/search?q=cache:-hfl5kT4RJ8J:msdn.microsoft.com/en-us/library/ms534019(VS.8
---
Unicode: Delphi
http://www.experts-exchange.com/Programming/Languages/Pascal/Delphi/Q_23279239.html
---
Unicode: Can you give an overview of links?
http://www.faqts.com/knowledge_base/view.phtml/aid/38864/fid/1852
===
Screencast: see also:
===
Table: see also:
===
Video: see also:
---
----------------------------------------------------------------------